Modern imaging systems generate large volumes of raw data under strict throughput and memory constraints. In Bayer Color Filter Array (CFA) sensors, conventional pipelines typically compress demosaiced RGB images, introducing redundancy and increasing computational cost. This motivates compression directly in the sensor domain. We propose BLADE, a GPU-oriented lossless compression framework that operates directly on CFA data. The method combines CFA-aware prediction with a block-and-stripe decomposition that enables fine-grained parallelism while preserving statistical efficiency. A lightweight global entropy model is employed to avoid synchronization overhead and ensure scalable parallel execution. Experimental results on high-resolution and high-bit-depth datasets show that BLADE achieves competitive or superior compression performance compared to state-of-the-art CFA methods, while significantly reducing execution time with respect to both conventional and GPU-based codecs. The method operates close to the Pareto-optimal frontier, achieving low bitrate and high throughput. System-level analysis under continuous acquisition demonstrates sustained real-time operation within a well-defined operating region. The method exhibits predictable behavior across resolutions, input rates, and power constraints, including on embedded GPU platforms. These results indicate that BLADE effectively bridges compression efficiency and real-time processing requirements, enabling high-throughput edge imaging systems.
Draft article: BLADE: Real-Time Lossless Compression of Bayer CFA Images on GPU Platforms (Draft PDF).
Download BLADE package (source code and scripts).
BLADE is a GPU-oriented lossless compression framework for Bayer Color Filter Array (CFA) images designed for high-throughput and real-time operation. The method operates directly in the RAW sensor domain, combining CFA-aware prediction with a block-and-stripe decomposition to enable fine-grained parallel execution on GPU platforms while preserving strong compression performance.
This Zenodo package provides the software and reproducibility material used in our study, including source code, experiment scripts, configuration files, and result figures. The experiments cover rate-time trade-offs, scalability across resolutions and bit depths, and system-level behavior under continuous acquisition.
Contents:
- BLADE source code
- Scripts to run benchmark and ablation experiments
- Plotting scripts and result figures
- Documentation for setup and execution
BLADE is intended for research and development in onboard and edge imaging systems where both compression efficiency and sustained throughput are required.
If the package link is not yet available, contact us at gici@uab.cat.
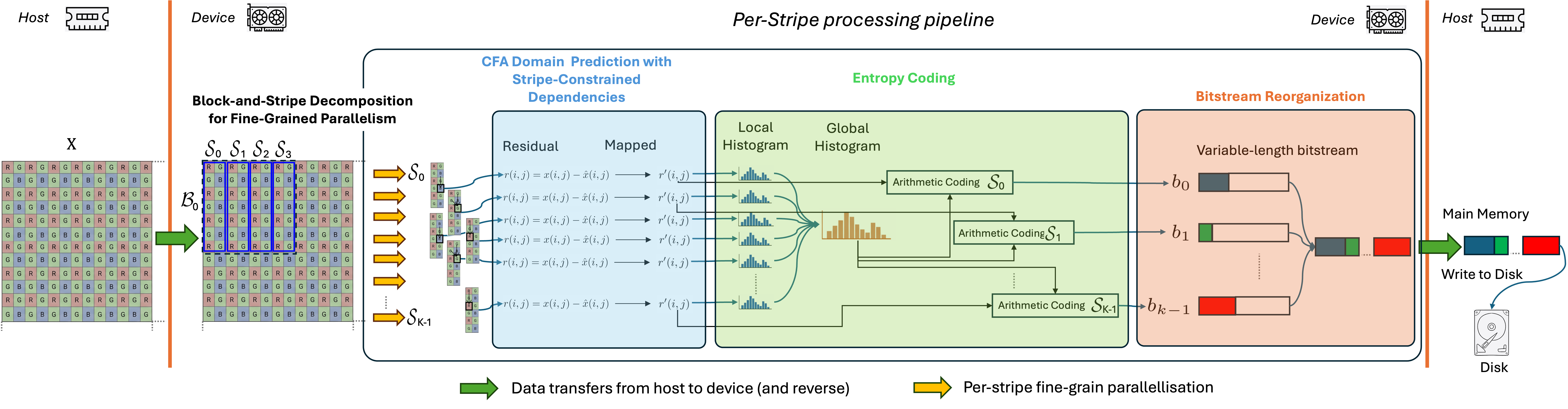
The pipeline processes CFA data directly in the sensor domain. Images are partitioned into blocks and stripes for independent prediction, entropy modeling, and encoding, and then compacted into the final compressed bitstream.
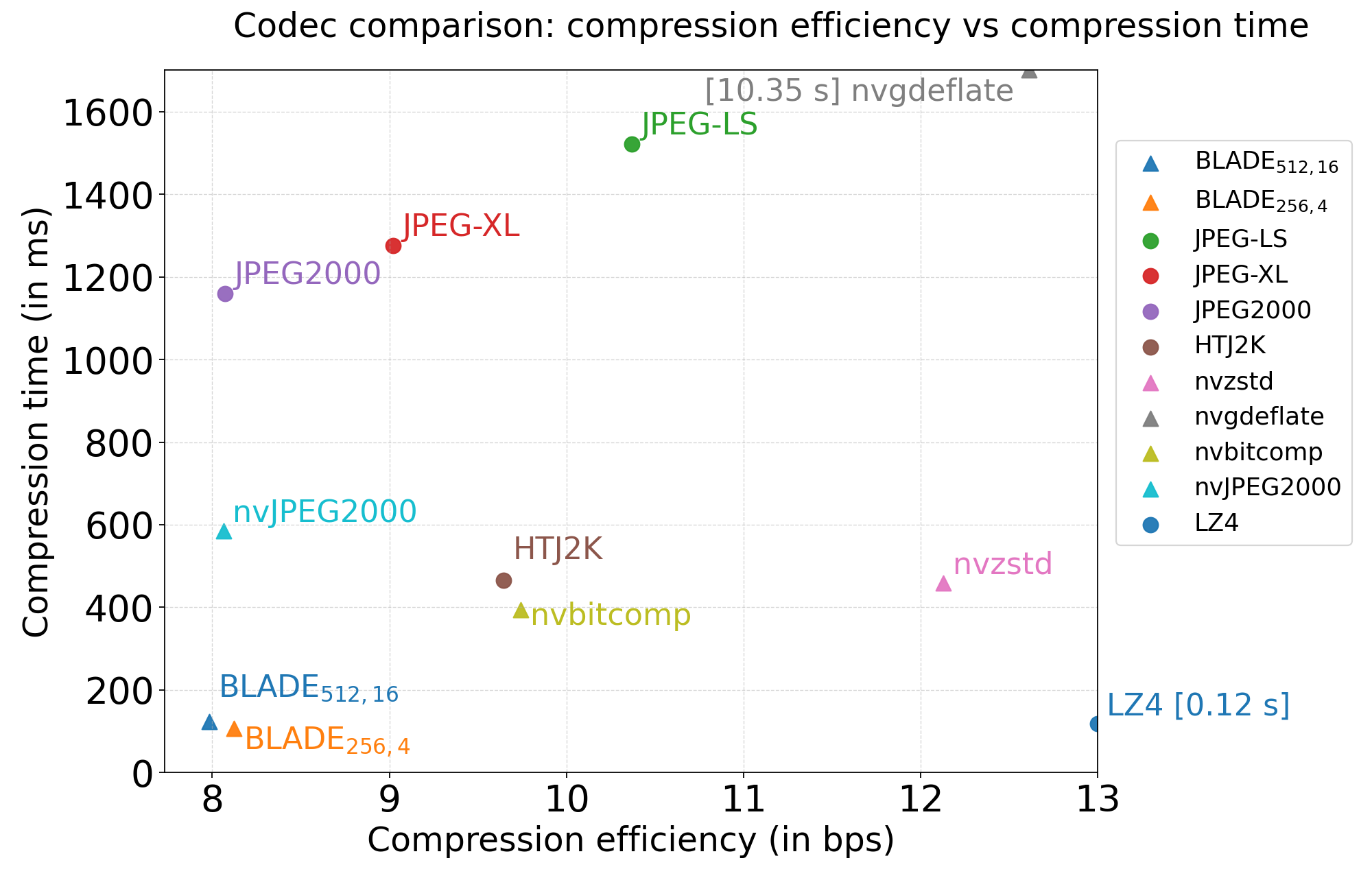
Rate-complexity trade-off (Pareto frontier). As reported in the paper, BLADE configurations operate near the lower-left region of the bitrate-time plane, combining low bitrate and reduced execution time with respect to both conventional and GPU-based codecs.
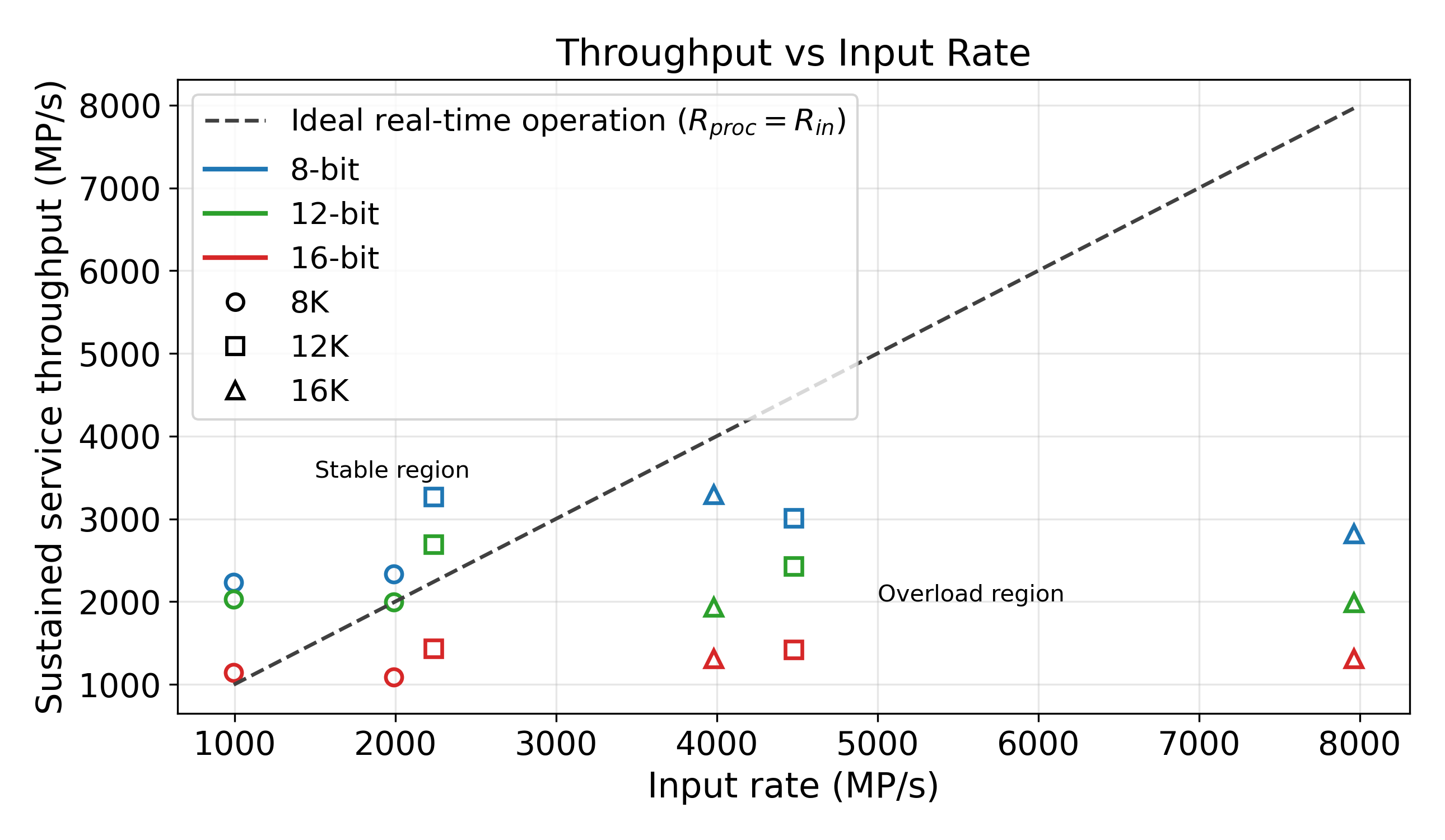
Operating region: sustained throughput vs input rate. The dashed diagonal marks the boundary Rproc = Rin. Points above the line indicate stable operation, while points below indicate overload and backlog growth.
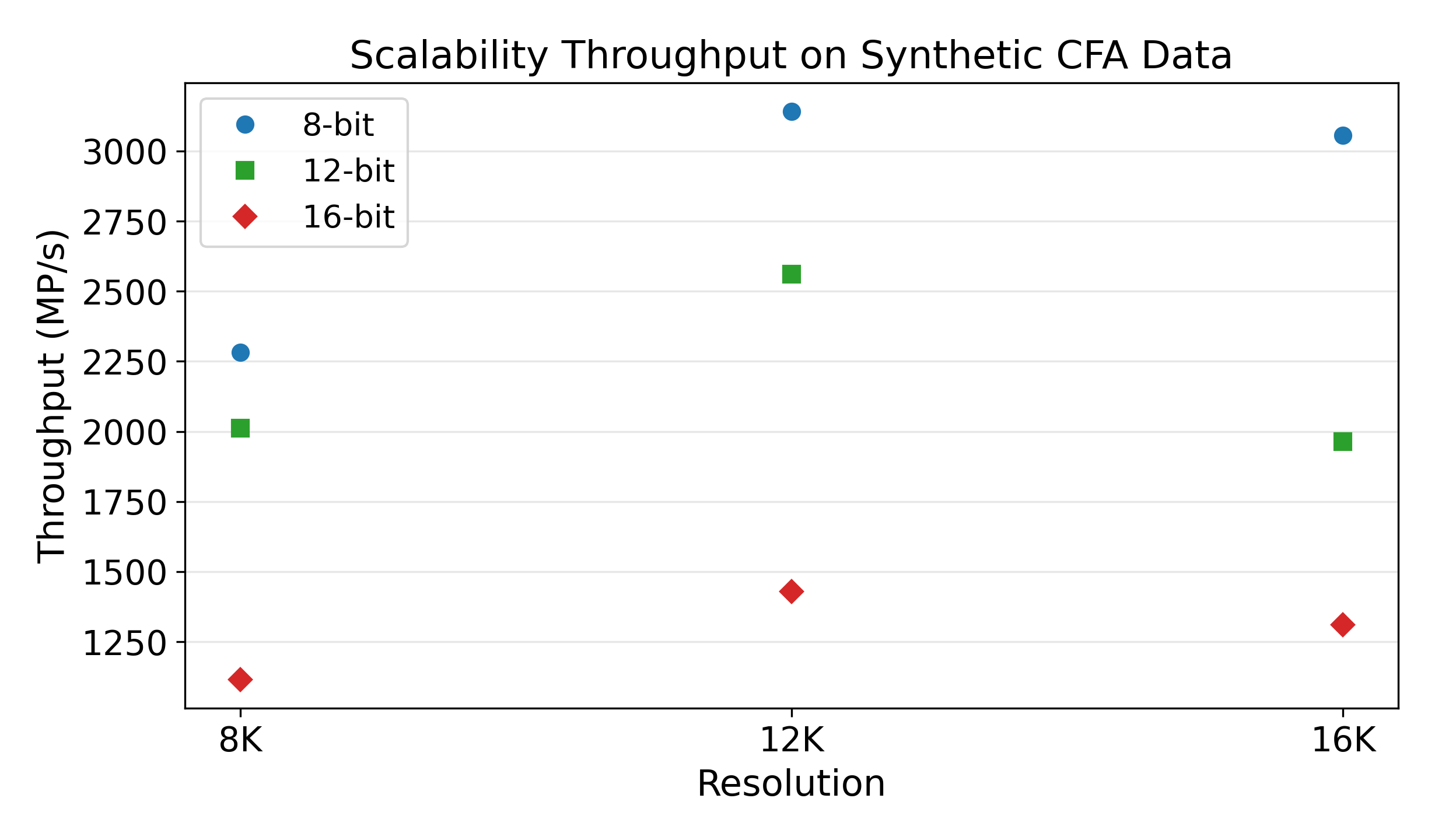
Scalability across resolutions and bit depth. In agreement with the article, throughput remains in the same overall range across 8K/12K/16K for each bit depth, confirming near-linear scaling with image size and predictable behavior.
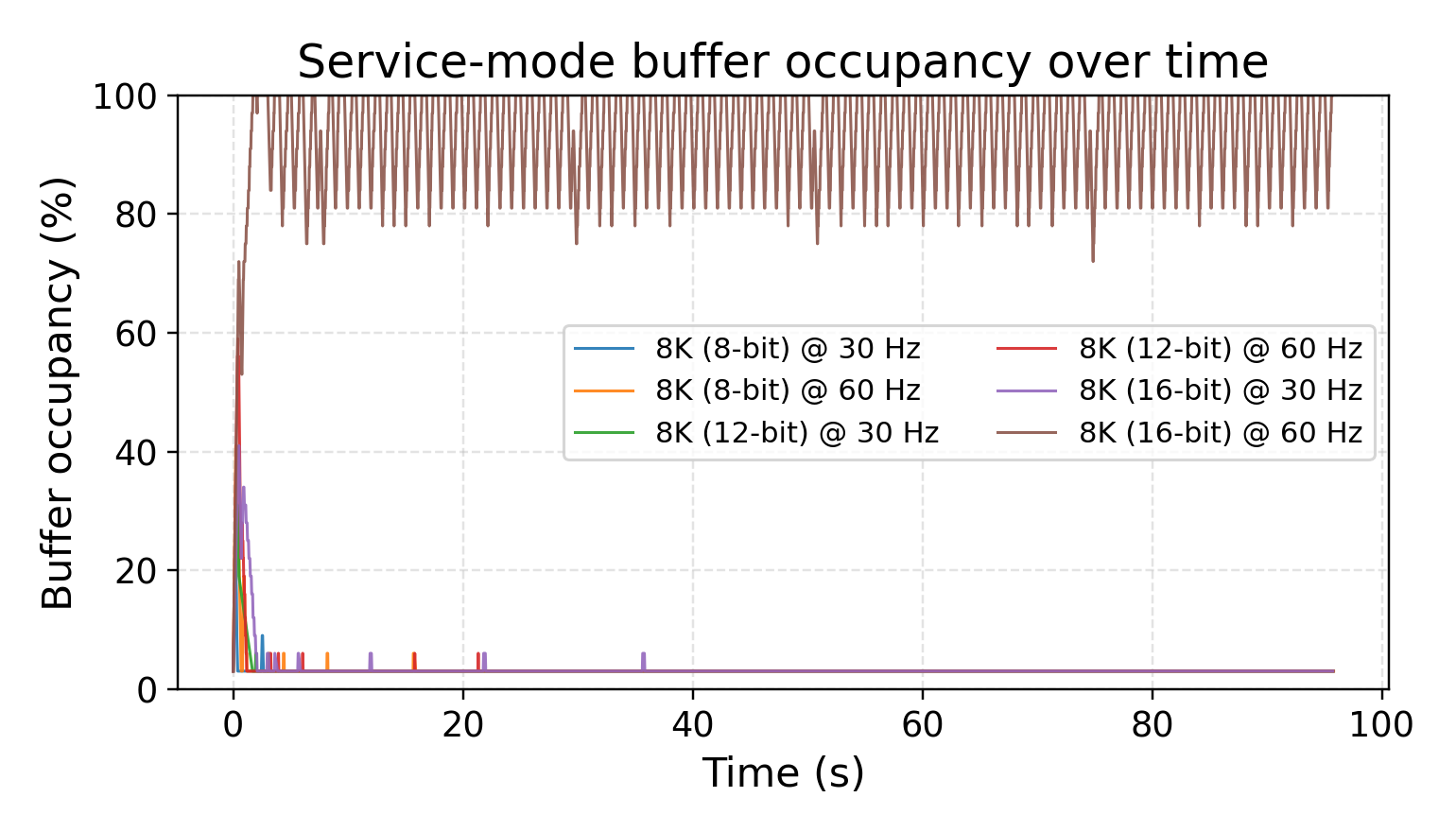
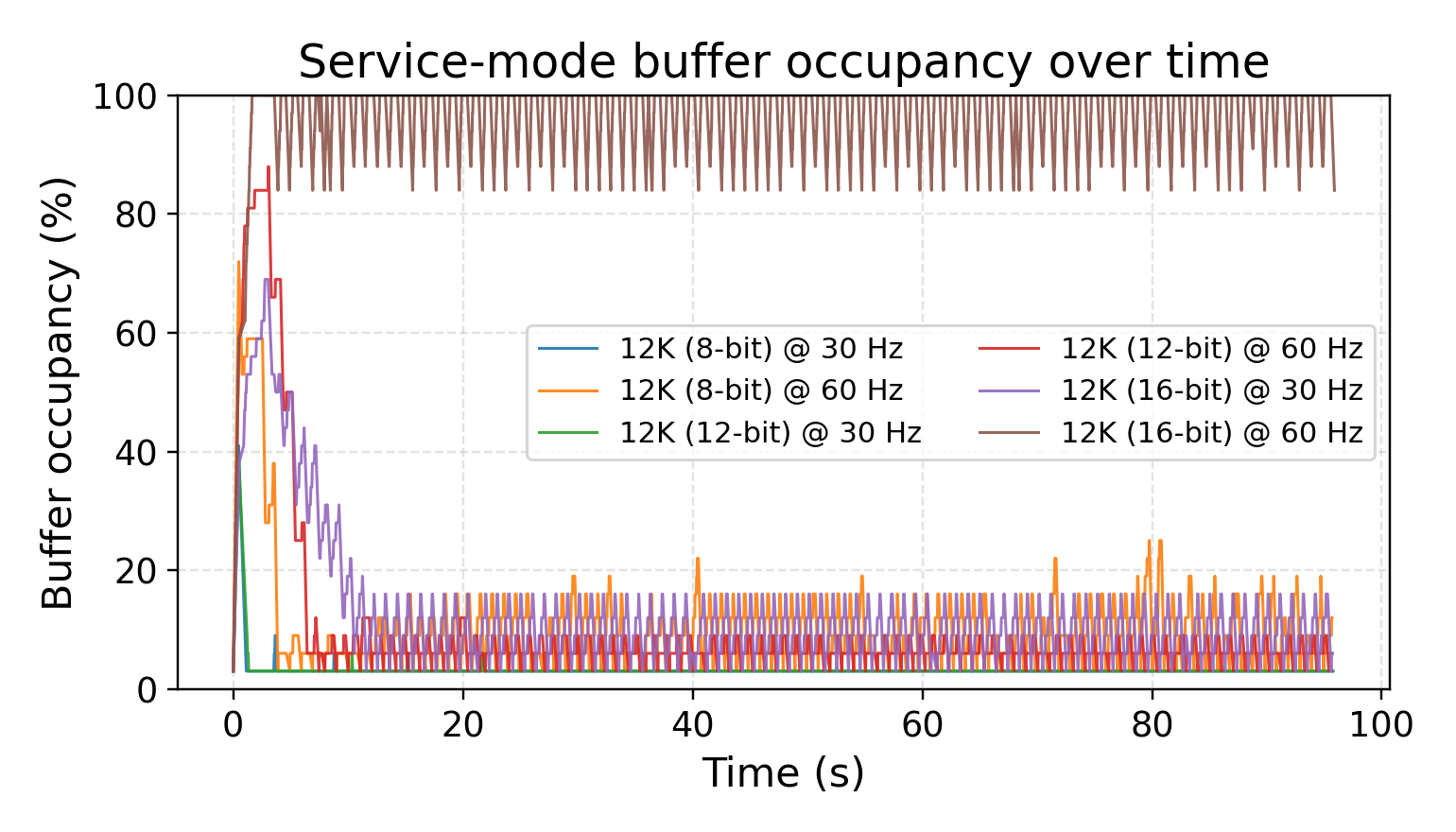
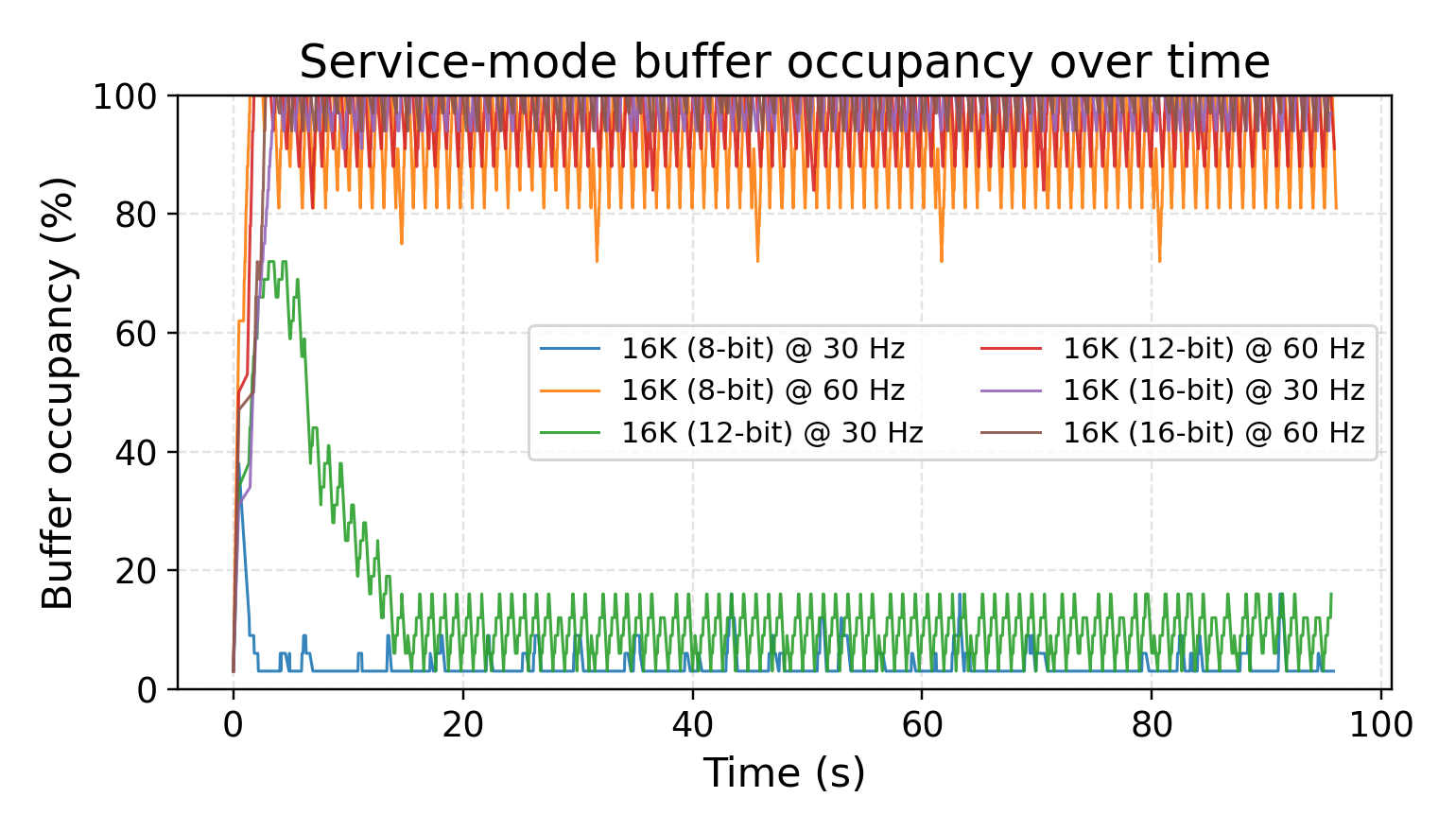
Continuous acquisition: buffer occupancy over time. These plots show the transition between stable and overload regimes at 8K, 12K, and 16K under different rates and bit depths, consistent with the system-level analysis in the paper.
The following checks can be used to reproduce representative results from the paper:
- Rate-throughput trade-off: evaluate two BLADE settings (BLADE512,16 and BLADE256,4) on Sony A7R IV RAW data and compare bitrate (bps) versus execution time (ms).
- Scalability: run synthetic CFA images at 8K/12K/16K and 8/12/16 bits to verify near-linear throughput behavior with resolution.
- Ablation: compare full BLADE against without prediction and uniform entropy model to confirm the bitrate increase reported in the paper.
For benchmarking, compare against JPEG-LS, JPEG XL, JPEG 2000/HTJ2K, LZ4 and GPU nvCOMP codecs as reported in the article.